High probability of component failures - requirement to
detect and recover promptly from such failures.
Common case: a lot of large files, (small files also
supported, but not optimised)
Support for large streaming reads as well as small random reads
Large appends the common use case (to be optimised for this)
Atomicity for concurrent appends, with minimal synchronisation overhead
High bandwidth over low latency - what does this mean?
You care about getting more data over vs low latency?
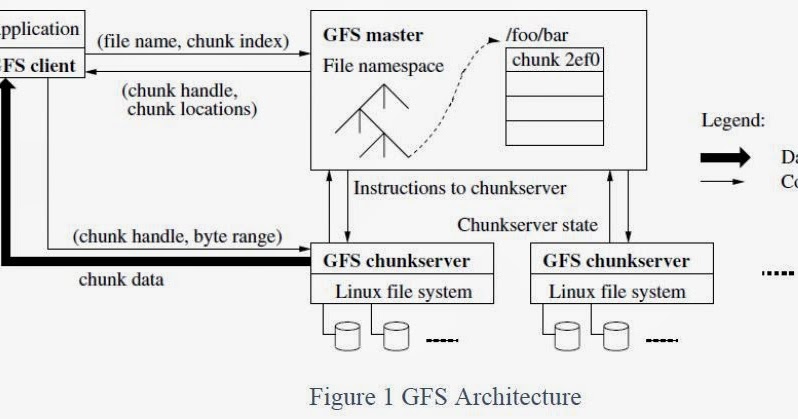
Architecture
Chunk size
Balancing between big and small chunk size
Larger chunk size: Pros
lesser chunks -> lesser metadata overhead on master server
With a large working set of file locations, client would still be
more able to comfortably cache all chunk information within local
memory
Cons
Space wastage due to internal fragmentation (mitigated with lazy allocation)
If a small file has little number of chunks, accessing the file
would cause the chunkservers to become hotspots (check paper for
mitigation)
Guarantees
How it works
The paper discusses this pretty well and in-depth.
Other interesting properties/mechanisms
Namespace management and locking
No per-directory data structure
When a new file is created:
Read locks acquired on all parent directories
Write lock is acquired on the new file
Implication:
Multiple clients can make new files on same directories
Read lock ensures that directory is not deleted when new file is
being created
Garbage collection and stale replication detection
Version numbers are maintained and reported periodically to master
server by the chunk servers
Checked again when a lease is about to be given to a chunkserver
Checksums
Computed on each chunkserver - why?
“Corruption” - referring to data being corrupted locally due to
equipment failure, as opposed to transport corruption.
Snapshotting
Goal: minimize interruptions of ongoing data.
Copy on write technique
When the master receives a snapshot
request, it first revokes any outstanding leases on the chunks
in the files it is about to snapshot.
It duplicates the metadata
for the source file or directory tree.
The master notices that the
reference count for chunk C is greater than one. It defers
replying to the client request and instead picks a new chunk handle C’. It then asks each chunkserver that has a current
replica of C to create a new chunk called C’.
(Local copy decreases overhead)
Questions:
Hadoop:
What does it run on? HDFS vs GFS?
GFS is an earlier version of HDFS
How about the checksum operation and I/O? what does this mean?
What happens if send IO before checksum is completed